
Vitalik neuer Artikel: Die mögliche Zukunft des Ethereum-Protokolls – The Verge

Tatsächlich benötigen wir mehrere Jahre, um einen Nachweis für die Validität des Ethereum-Konsenses zu erhalten.
Tatsächlich benötigen wir Jahre, um einen Gültigkeitsbeweis für den Ethereum-Konsens zu erhalten.
Originaltitel: 《Possible futures of the Ethereum protocol, part 4: The Verge》
Autor: Vitalik Buterin
Übersetzung: Mensh, ChainCatcher
Besonderer Dank gilt Justin Drake, Hsia-wei Wanp, Guillaume Ballet, Icinacio, Rosh Rudolf, Lev Soukhanoy, Ryan Sean Adams und Uma Roy für ihr Feedback und ihre Durchsicht.
Eines der mächtigsten Merkmale der Blockchain ist, dass jeder auf seinem eigenen Computer einen Node betreiben und die Korrektheit der Blockchain verifizieren kann. Selbst wenn 9596 Nodes, die den Chain-Konsens (PoW, PoS) ausführen, sofort einer Regeländerung zustimmen und beginnen, Blöcke nach den neuen Regeln zu produzieren, wird jeder, der einen vollständig verifizierenden Node betreibt, die Chain ablehnen. Coin-Maker, die nicht Teil dieser Verschwörung sind, werden sich automatisch auf eine Chain konzentrieren, die weiterhin den alten Regeln folgt, und diese Chain weiter aufbauen, während vollständig verifizierende Nutzer dieser Chain folgen werden.
Dies ist der entscheidende Unterschied zwischen Blockchain und zentralisierten Systemen. Damit dieses Merkmal jedoch Bestand hat, muss es für genügend Menschen tatsächlich machbar sein, einen vollständig verifizierenden Node zu betreiben. Dies gilt sowohl für Blockproduzenten (denn wenn diese die Chain nicht verifizieren, tragen sie nicht zur Durchsetzung der Protokollregeln bei) als auch für normale Nutzer. Heute ist es möglich, einen Node auf einem Consumer-Laptop (einschließlich des Laptops, auf dem dieser Artikel geschrieben wurde) zu betreiben, aber es ist schwierig. The Verge soll dies ändern, indem die Berechnungskosten für die vollständige Verifizierung der Chain gesenkt werden, sodass jede Mobile Wallet, Browser Wallet oder sogar Smartwatch standardmäßig verifizieren kann.
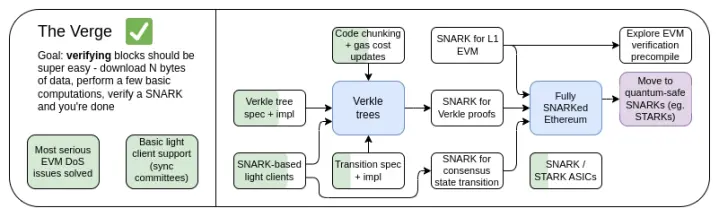
The Verge 2023 Roadmap
Ursprünglich bezog sich „Verge“ auf die Übertragung des Ethereum-Statusspeichers auf Verkle-Bäume – eine baumartige Struktur, die kompaktere Beweise ermöglicht und eine zustandslose Verifizierung von Ethereum-Blöcken erlaubt. Ein Node kann einen Ethereum-Block verifizieren, ohne irgendeinen Ethereum-Status (Kontostände, Vertragscode, Speicher ...) auf seiner Festplatte zu speichern, wobei als Preis einige hundert KB an Beweisdaten und einige hundert Millisekunden zusätzliche Zeit für die Verifizierung eines Beweises anfallen. Heute steht Verge für eine größere Vision, die sich auf die maximale Ressourceneffizienz der Verifizierung der Ethereum-Chain konzentriert, einschließlich zustandsloser Verifizierungstechnologien und der Verwendung von SNARKs zur Verifizierung aller Ethereum-Ausführungen.
Neben dem langfristigen Fokus auf SNARK-Verifizierung der gesamten Chain gibt es eine neue Frage, ob Verkle-Bäume die optimale Technologie sind. Verkle-Bäume sind anfällig für Angriffe von Quantencomputern, daher müssten wir, wenn wir die aktuellen KECCAK Merkle Patricia Trees durch Verkle-Bäume ersetzen, diese später erneut austauschen. Die selbstersetzende Methode für Merkle-Bäume besteht darin, direkt STARKs mit Merkle-Branches in einen Binärbaum zu verwenden. Historisch galt dies wegen Overhead und technischer Komplexität als nicht praktikabel. Kürzlich jedoch hat Starkware auf einem Laptop mit ckcle STARKs 1,7 Millionen Poseidon-Hashes pro Sekunde bewiesen, und durch Technologien wie GKB verkürzt sich die Beweiszeit für weitere „traditionelle“ Hashes rapide. Daher ist „Verge“ im letzten Jahr offener geworden und hat mehrere Möglichkeiten.
The Verge: Zentrale Ziele
- Zustandslose Clients: Der für vollständig verifizierende Clients und Markernodes benötigte Speicherplatz sollte nur wenige GB betragen.
- (Langfristig) Vollständige Verifizierung der Chain (Konsens und Ausführung) auf einer Smartwatch. Einige Daten herunterladen, SNARK verifizieren, fertig.
In diesem Kapitel
- Zustandslose Clients: Verkle oder STARKs
- Gültigkeitsbeweise für EVM-Ausführung
- Gültigkeitsbeweise für den Konsens
Zustandslose Verifizierung: Verkle oder STARKs
Welches Problem wollen wir lösen?
Heute müssen Ethereum-Clients Hunderte von Gigabyte an Statusdaten speichern, um Blöcke zu verifizieren, und diese Menge wächst jedes Jahr. Die Rohdaten des Status wachsen jährlich um etwa 30GB, und ein einzelner Client muss zusätzliche Daten speichern, um Triplets effizient zu aktualisieren.
Dies reduziert die Anzahl der Nutzer, die einen vollständig verifizierenden Ethereum-Node betreiben können: Obwohl große Festplatten, die alle Ethereum-Statusdaten und sogar jahrelange Historie speichern können, weit verbreitet sind, kaufen die meisten Menschen Computer mit nur wenigen Hundert Gigabyte Speicherplatz. Die Statusgröße erschwert auch den Prozess der erstmaligen Node-Einrichtung erheblich: Der Node muss den gesamten Status herunterladen, was Stunden oder Tage dauern kann. Dies hat verschiedene Kettenreaktionen zur Folge. Zum Beispiel erschwert es Node-Betreibern das Upgrade ihrer Node-Einstellungen erheblich. Technisch kann das Upgrade ohne Ausfallzeit erfolgen – einen neuen Client starten, warten, bis er synchronisiert ist, dann den alten Client abschalten und die Schlüssel übertragen – aber in der Praxis ist dies technisch sehr komplex.
Wie funktioniert das?
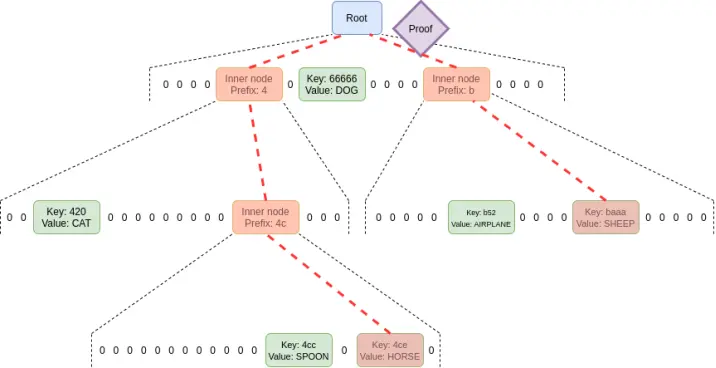
Zustandslose Verifizierung ist eine Technik, die es Nodes erlaubt, Blöcke zu verifizieren, ohne den gesamten Status zu besitzen. Stattdessen wird jedem Block ein Zeuge beigefügt, der Folgendes enthält: (i) Werte, Code, Salden, Speicher an bestimmten Positionen im Status, auf die der Block zugreifen wird; (ii) kryptografische Beweise, dass diese Werte korrekt sind.
Um zustandslose Verifizierung zu ermöglichen, muss die Struktur des Ethereum-Statusbaums geändert werden. Der aktuelle Merkle Patricia Tree ist für jede kryptografische Beweismethode, insbesondere im schlimmsten Fall, extrem ungeeignet. Das gilt sowohl für „native“ Merkle-Branches als auch für STARK-Verpackungen. Die Hauptschwierigkeiten ergeben sich aus einigen Schwächen des MPT:
1. Es handelt sich um einen Hexadezimalbaum (jeder Knoten hat 16 Kinder). Das bedeutet, dass in einem Baum der Größe N ein Beweis im Durchschnitt 32*(16-1)*log16(N) = 120*log2(N) Bytes benötigt, oder etwa 3840 Bytes bei einem Baum mit 2^32 Einträgen. Ein Binärbaum benötigt nur 32*(2-1)*log2(N) = 32*log2(N) Bytes, also etwa 1024 Bytes.
2. Code ist nicht Merkle-isiert. Das bedeutet, dass für jeden Zugriff auf den Account-Code der gesamte Code bereitgestellt werden muss, maximal 24000 Bytes.
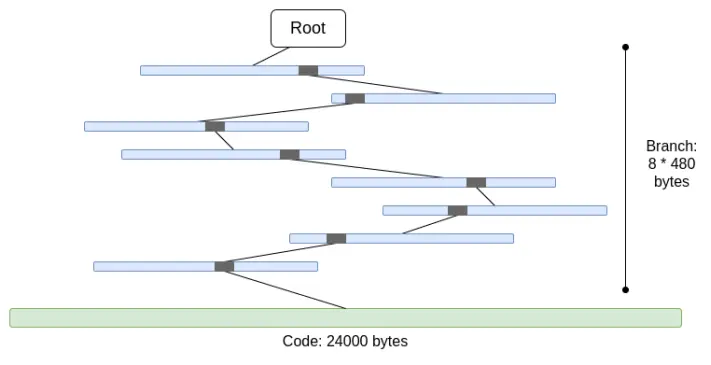
Wir können den schlimmsten Fall wie folgt berechnen:
30000000 gas / 2400 (Kosten für das Lesen eines kalten Accounts) * (5 * 488 + 24000) = 330000000 Bytes
Die Kosten für Branches sind etwas niedriger (5*480 statt 8*480), da sich bei vielen Branches die oberen Teile wiederholen. Dennoch ist die Datenmenge, die in einem Slot heruntergeladen werden muss, völlig unrealistisch. Wenn wir versuchen, dies mit STARK zu verpacken, stoßen wir auf zwei Probleme: (i) KECCAK ist für STARK relativ ungeeignet; (ii) 330MB Daten bedeuten, dass wir 5 Millionen Aufrufe der KECCAK-Rundfunktion beweisen müssen, was für alle außer den leistungsstärksten Consumer-Hardware wahrscheinlich nicht beweisbar ist, selbst wenn wir die Effizienz von STARK-Beweisen für KECCAK verbessern könnten.
Wenn wir den Hexadezimalbaum direkt durch einen Binärbaum ersetzen und den Code zusätzlich Merkle-isieren, ergibt sich im schlimmsten Fall etwa 30000000/2400*32*(32-14+8) = 10400000 Bytes (14 ist die Subtraktion für redundante Bits bei 2^14 Branches, 8 ist die Beweislänge für den Eintritt in den Codeblock-Leaf). Beachten Sie, dass dies eine Änderung der Gas-Kosten erfordert, wobei für den Zugriff auf jeden einzelnen Codeblock eine Gebühr erhoben wird; EIP-4762 macht genau das. 10,4 MB sind deutlich besser, aber für viele Nodes ist das Herunterladen dieser Datenmenge in einem Slot immer noch zu viel. Daher benötigen wir leistungsfähigere Technologien. Zwei führende Lösungen sind hier: Verkle-Bäume und STARKed Binär-Hash-Bäume.
Verkle-Bäume
Verkle-Bäume verwenden elliptische Kurven-basierte Vektorcommitments für kürzere Beweise. Der Schlüssel ist, dass unabhängig von der Breite des Baums jeder Parent-Child-Beweisteil nur 32 Bytes groß ist. Die einzige Begrenzung der Baumweite ist, dass bei zu großer Breite die Berechnungseffizienz der Beweise sinkt. Die vorgeschlagene Implementierung für Ethereum verwendet eine Breite von 256.
Daher beträgt die Größe eines einzelnen Branches im Beweis 32 - log256(N) = 4*log2(N) Bytes. Die theoretisch maximale Beweisgröße beträgt also etwa 30000000 / 2400 * 32 * (32 -14 + 8) / 8 = 130000 Bytes (tatsächlich variiert dies leicht aufgrund ungleichmäßiger Statusblockverteilung, aber als Näherung ist es brauchbar).
Beachten Sie außerdem, dass in allen obigen Beispielen dieser „schlimmste Fall“ nicht der schlimmste ist: Ein noch schlimmerer Fall wäre, wenn ein Angreifer absichtlich zwei Adressen „mined“, sodass sie im Baum ein langes gemeinsames Präfix haben, und von einer dieser Adressen Daten liest, was die Branchlänge im schlimmsten Fall verdoppeln kann. Selbst dann beträgt die schlimmste Beweislänge für Verkle-Bäume 2,6MB, was mit den aktuellen schlimmsten Fällen für Prüfdaten vergleichbar ist.
Wir nutzen diese Beobachtung auch für einen weiteren Punkt: Der Zugriff auf „benachbarte“ Speicherbereiche wird sehr günstig: entweder viele Codeblöcke desselben Vertrags oder benachbarte Speicher-Slots. EIP-4762 definiert Nachbarschaft und erhebt für benachbarte Zugriffe nur 200 Gas. In diesem Fall beträgt die schlimmste Beweisgröße 30000000 / 200*32 - 4800800 Bytes, was immer noch im Toleranzbereich liegt. Um diesen Wert weiter zu reduzieren, könnte man die Kosten für benachbarte Zugriffe leicht erhöhen.
STARKed Binär-Hash-Baum
Das Prinzip dieser Technik ist selbsterklärend: Man erstellt einfach einen Binärbaum, erhält maximal 10,4 MB Beweis, beweist die Werte im Block und ersetzt dann den Beweis durch einen STARK. Der Beweis selbst enthält nur die zu beweisenden Daten plus einen festen Overhead von 100-300kB durch den eigentlichen STARK.
Die Haupt-Herausforderung hier ist die Verifizierungszeit. Wir können eine ähnliche Rechnung wie oben machen, nur dass wir Hashes statt Bytes zählen. Ein 10,4 MB Block bedeutet 330000 Hashes. Wenn ein Angreifer Adressen mit langem gemeinsamen Präfix im Adressbaum „mined“, steigt die Zahl im schlimmsten Fall auf etwa 660000 Hashes. Wenn wir 200.000 Hashes pro Sekunde beweisen können, ist das kein Problem.
Mit dem Poseidon-Hash auf Consumer-Laptops werden diese Zahlen bereits erreicht, und Poseidon wurde speziell für STARK-Freundlichkeit entwickelt. Allerdings ist das Poseidon-System noch relativ unreif, sodass viele seiner Sicherheit noch nicht vertrauen. Daher gibt es zwei realistische Wege:
- Schnelle und umfangreiche Sicherheitsanalyse von Poseidon, um genügend Vertrauen für den Einsatz auf L1 zu gewinnen
- Verwendung konservativerer Hashfunktionen wie SHA256 oder BLAKE
Für konservative Hashfunktionen kann der STARK-Kreis von Starkware zum Zeitpunkt des Schreibens auf Consumer-Laptops nur 10-30k Hashes pro Sekunde beweisen. Aber die STARK-Technologie verbessert sich schnell. Schon heute zeigen GKR-basierte Techniken, dass diese Geschwindigkeit auf 100-200k gesteigert werden kann.
Weitere Anwendungsfälle für Zeugen außerhalb der Blockverifizierung
Neben der Blockverifizierung gibt es drei weitere wichtige Anwendungsfälle für effizientere zustandslose Verifizierung:
- Mempool: Wenn Transaktionen gesendet werden, müssen Nodes im P2P-Netzwerk die Transaktion verifizieren, bevor sie sie weiterleiten. Heute umfasst die Verifizierung die Signaturprüfung sowie die Überprüfung des Saldos und des Nonce. In Zukunft (z.B. mit nativer Account-Abstraktion wie EIP-7701) könnte dies das Ausführen von EVM-Code beinhalten, der Statuszugriffe durchführt. Wenn der Node zustandslos ist, muss die Transaktion einen Beweis für die Statusobjekte enthalten.
- Inclusion Lists: Dies ist ein vorgeschlagenes Feature, das es (möglicherweise kleineren und weniger komplexen) Proof-of-Stake-Validatoren erlaubt, zu erzwingen, dass eine Transaktion im nächsten Block enthalten ist, unabhängig vom Willen der (möglicherweise größeren und komplexeren) Blockbauer. Das würde die Fähigkeit von Mächtigen schwächen, die Blockchain durch Transaktionsverzögerung zu manipulieren. Validatoren müssen jedoch die Gültigkeit der Inclusion List-Transaktionen verifizieren können.
- Light Clients: Wenn Nutzer über Wallets auf die Chain zugreifen (wie Metamask, Rainbow, Rabby usw.), müssen sie einen Light Client (wie Helios) betreiben. Das Kernmodul von Helios liefert den Nutzern einen verifizierten Status-Root. Für ein vollständig vertrauensloses Erlebnis muss der Nutzer für jeden RPC-Call einen Beweis liefern (z.B. für einen eth_call muss der Nutzer alle während des Calls gelesenen Status beweisen).
Allen diesen Anwendungsfällen ist gemeinsam, dass sie viele, aber jeweils kleine Beweise benötigen. Daher sind STARK-Beweise für sie nicht sinnvoll; stattdessen ist es am realistischsten, direkt Merkle-Branches zu verwenden. Ein weiterer Vorteil von Merkle-Branches ist ihre Update-Fähigkeit: Hat man einen Beweis für ein Statusobjekt mit Root B, kann man ihn mit einem Sub-Block B2 und dessen Zeugen auf Root B2 aktualisieren. Verkle-Beweise sind ebenfalls nativ update-fähig.
Bezug zu bestehender Forschung:
- Verkle trees
- John Kuszmauls Originalarbeit zu Verkle trees
- Starkware
- Poseidon2 paper
- Ajtai (schnelle Hashfunktionen auf Basis von Lattice-Härte)
- Verkle.info
Was bleibt zu tun?
Die Hauptaufgaben sind:
1. Weitere Analyse der Folgen von EIP-4762 (Änderungen der zustandslosen Gas-Kosten)
2. Weitere Arbeit an der Fertigstellung und dem Testen des Übergangsprozesses, der der Hauptteil der Komplexität jeder zustandslosen Implementierung ist
3. Weitere Sicherheitsanalysen für Poseidon, Ajtai und andere „STARK-freundliche“ Hashfunktionen
4. Entwicklung extrem effizienter STARK-Protokollfunktionen für „konservative“ (oder „traditionelle“) Hashes, z.B. auf Basis von Binius oder GKR.
Außerdem werden wir bald eine Entscheidung zwischen drei Optionen treffen: (i) Verkle-Bäume, (ii) STARK-freundliche Hashfunktionen und (iii) konservative Hashfunktionen. Ihre Eigenschaften sind in der folgenden Tabelle zusammengefasst:
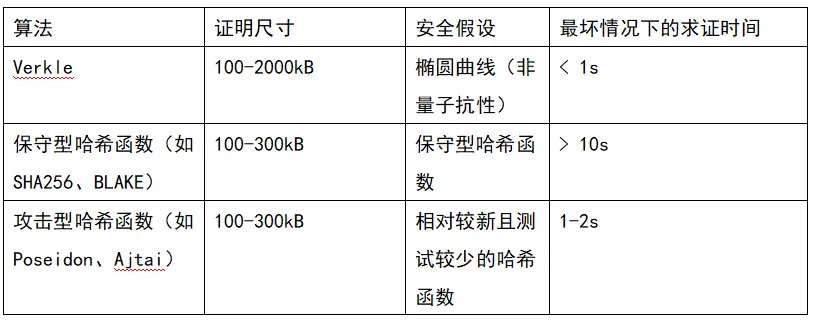
Neben diesen „Headline-Zahlen“ gibt es weitere wichtige Überlegungen:
- Der Verkle-Baum-Code ist heute bereits ziemlich ausgereift. Jede andere Lösung würde die Implementierung verzögern und wahrscheinlich einen Hard Fork verschieben. Das ist nicht schlimm, besonders wenn wir mehr Zeit für Hash-Analysen oder Validator-Implementierungen brauchen oder andere wichtige Features früher in Ethereum aufnehmen wollen.
- Das Aktualisieren des Status-Roots mit Hashes ist schneller als mit Verkle-Bäumen. Das bedeutet, dass hashbasierte Methoden die Synchronisationszeit für Full Nodes senken können.
- Verkle-Bäume haben interessante Update-Eigenschaften für Zeugen – Verkle-Zeugen sind update-fähig. Das ist für Mempool, Inclusion Lists und andere Anwendungsfälle nützlich und kann die Implementierung effizienter machen: Wird ein Statusobjekt aktualisiert, kann man den Zeugen der vorletzten Ebene aktualisieren, ohne die letzte Ebene zu lesen.
- Verkle-Bäume sind schwieriger für SNARK-Beweise. Wenn wir die Beweisgröße auf wenige Tausend Bytes reduzieren wollen, bringen Verkle-Beweise Schwierigkeiten mit sich. Das liegt daran, dass die Verifizierung von Verkle-Beweisen viele 256-Bit-Operationen erfordert, was entweder viel Overhead für das Beweissystem bedeutet oder ein eigenes internes Design mit 256-Bit-Verkle-Beweisteilen erfordert. Für Zustandslosigkeit ist das kein Problem, aber es erschwert andere Dinge.
Wenn wir Verkle-Zeugen-Updatefähigkeit quantensicher und effizient erreichen wollen, ist eine weitere Möglichkeit ein auf Lattice basierender Merkle-Baum.
Wenn das Beweissystem im schlimmsten Fall nicht effizient genug ist, können wir das mit dem unerwarteten Werkzeug Multi-Dimensional Gas ausgleichen: Separate Gas-Limits für (i) calldata, (ii) Berechnung, (iii) Statuszugriffe und ggf. weitere Ressourcen. Multi-Dimensional Gas erhöht die Komplexität, aber im Gegenzug begrenzt es das Verhältnis von Durchschnitts- zu Worst-Case strenger. Mit Multi-Dimensional Gas kann die maximale Branch-Anzahl, die bewiesen werden muss, von 12500 auf z.B. 3000 sinken. Damit wäre BLAKE3 schon heute (gerade so) ausreichend.
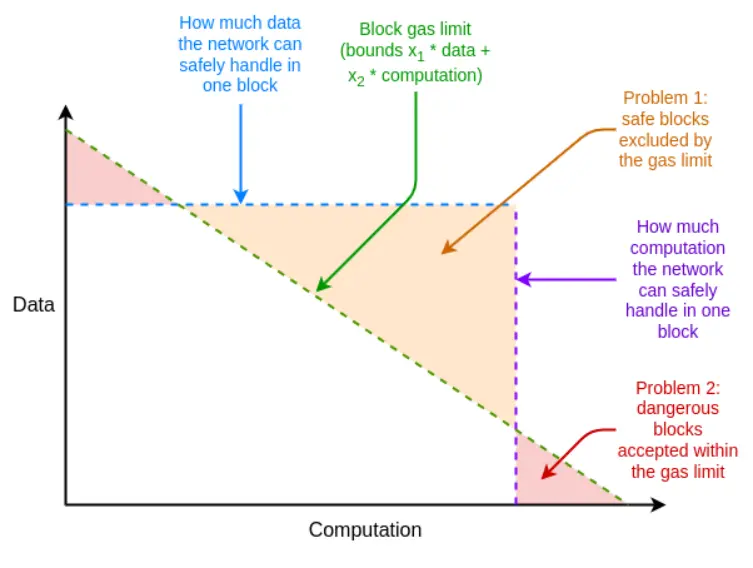
Multi-Dimensional Gas ermöglicht, dass die Ressourcenlimits eines Blocks näher an die Hardware-Limits herankommen
Ein weiteres unerwartetes Werkzeug ist, die Status-Root-Berechnung auf den Slot nach dem Block zu verschieben. Dann haben wir volle 12 Sekunden Zeit, um den Status-Root zu berechnen, was bedeutet, dass selbst im Extremfall 60000 Hashes pro Sekunde für den Beweis ausreichen – auch hier wäre BLAKE3 gerade so ausreichend.
Der Nachteil dieser Methode ist eine Slot-Latenz für Light Clients, aber es gibt clevere Techniken, um diese Latenz auf die Beweiserzeugung zu reduzieren. Beispielsweise kann der Beweis sofort nach seiner Erzeugung im Netzwerk verbreitet werden, ohne auf den nächsten Block zu warten.
Wie interagiert das mit anderen Teilen der Roadmap?
Die Lösung des Zustandslosigkeitsproblems erhöht die Schwierigkeit für Single-Staker erheblich. Wenn es Technologien gibt, die das Mindestguthaben für Single-Staking senken, wie Orbit SSF oder Anwendungsschicht-Strategien wie Squad Staking, wird dies praktikabler.
Wenn gleichzeitig EOF eingeführt wird, wird die Multi-Dimensional-Gas-Analyse einfacher. Das liegt daran, dass die Hauptkomplexität von Multi-Dimensional Gas aus der Behandlung von Subcalls resultiert, die nicht das gesamte Gas des Parent-Calls weitergeben. EOF kann solche Subcalls einfach für illegal erklären, was das Problem trivial macht (und native Account-Abstraktion bietet eine Protokollalternative für die aktuellen Hauptanwendungsfälle von Partial Gas).
Zwischen zustandsloser Verifizierung und History Expiry gibt es eine wichtige Synergie. Heute müssen Clients fast 1TB an historischen Daten speichern; das ist ein Vielfaches der Statusdaten. Selbst wenn Clients zustandslos sind, bleibt der Traum vom speicherlosen Client unerreichbar, solange sie für die Speicherung historischer Daten verantwortlich sind. Der erste Schritt ist EIP-4444, was bedeutet, dass historische Daten in Torrents oder im Portal Network gespeichert werden.
Gültigkeitsbeweise für EVM-Ausführung
Welches Problem wollen wir lösen?
Das langfristige Ziel der Ethereum-Blockverifizierung ist klar – es sollte möglich sein, einen Ethereum-Block wie folgt zu verifizieren: (i) Block herunterladen, oder sogar nur einen kleinen Teil der Data-Availability-Samples; (ii) einen kleinen Beweis für die Blockgültigkeit verifizieren. Das wäre eine extrem ressourcensparende Operation, die auf Mobile Clients, Browser Wallets und sogar auf einer anderen Chain (ohne Data Availability) durchgeführt werden kann.
Dazu müssen sowohl (i) die Konsensschicht (Proof of Stake) als auch (ii) die Ausführungsschicht (EVM) mit SNARK oder STARK bewiesen werden. Ersteres ist eine Herausforderung, die im Zuge der weiteren Verbesserung der Konsensschicht (z.B. für Single-Slot-Finality) gelöst werden sollte. Letzteres erfordert einen Beweis für die EVM-Ausführung.
Was ist das und wie funktioniert es?
Formal ist die EVM in der Ethereum-Spezifikation als Statusübergangsfunktion definiert: Man hat einen Vor-Status S, einen Block B, und berechnet einen Nach-Status S' = STF(S, B). Wenn Nutzer einen Light Client verwenden, besitzen sie S und S' nicht vollständig, nicht einmal E; sie haben stattdessen einen Vor-Status-Root R, einen Nach-Status-Root R' und einen Block-Hash H.
- Öffentliche Eingaben: Vor-Status-Root R, Nach-Status-Root R', Block-Hash H
- Private Eingaben: Blockkörper B, Statusobjekte, auf die Block Q zugreift, dieselben Objekte nach Ausführung von Q', Statusbeweise (z.B. Merkle-Branches) P
- Behauptung 1: P ist ein gültiger Beweis, dass Q bestimmte Teile des von R repräsentierten Status enthält
- Behauptung 2: Wenn man STF auf Q ausführt, (i) greift der Ausführungsprozess nur auf Objekte innerhalb von Q zu, (ii) der Block ist gültig, (iii) das Ergebnis ist Q'
- Behauptung 3: Wenn man mit Q' und P den neuen Status-Root berechnet, erhält man R'
Wenn das gegeben ist, kann man einen vollständig verifizierenden Light Client für die Ethereum-EVM-Ausführung haben. Das macht die Ressourcenanforderungen für Clients sehr niedrig. Für einen wirklich vollständig verifizierenden Ethereum-Client muss dasselbe für den Konsens gemacht werden.
Implementierungen von Gültigkeitsbeweisen für EVM-Berechnungen existieren bereits und werden auf L2 breit eingesetzt. Damit EVM-Gültigkeitsbeweise auf L1 praktikabel werden, ist jedoch noch viel Arbeit nötig.
Bezug zu bestehender Forschung?
- EFPSE ZK-EVM (eingestellt wegen besserer Alternativen)
- Zeth, das die EVM in RISC-0 ZK-VM kompiliert
- ZK-EVM formale Verifizierungsprojekte
Was bleibt zu tun?
Heute gibt es bei Gültigkeitsbeweisen für elektronische Buchführung zwei Schwächen: Sicherheit und Verifizierungszeit.
Ein sicherer Gültigkeitsbeweis muss garantieren, dass der SNARK tatsächlich die EVM-Berechnung verifiziert und keine Schwachstellen existieren. Zwei Haupttechniken zur Erhöhung der Sicherheit sind Multi-Validatoren und formale Verifizierung. Multi-Validatoren bedeutet, dass es mehrere unabhängig implementierte Gültigkeitsbeweise gibt, wie mehrere Clients, und ein Block wird akzeptiert, wenn ein ausreichend großer Teil dieser Implementierungen ihn beweist. Formale Verifizierung nutzt Tools wie Lean4, die normalerweise für mathematische Beweise verwendet werden, um zu beweisen, dass der Gültigkeitsbeweis nur korrekte Ausführungen der EVM-Spezifikation akzeptiert (z.B. EVM K Semantik oder die in Python geschriebene Ethereum Execution Layer Specification (EELS)).
Eine ausreichend schnelle Verifizierungszeit bedeutet, dass jeder Ethereum-Block in weniger als 4 Sekunden verifiziert werden kann. Heute sind wir davon noch weit entfernt, obwohl wir dem Ziel näher sind als vor zwei Jahren. Um dieses Ziel zu erreichen, müssen wir in drei Richtungen Fortschritte machen:
- Parallelisierung – Der schnellste EVM-Verifizierer kann heute einen Ethereum-Block im Durchschnitt in 15 Sekunden beweisen. Das wird erreicht, indem die Arbeit auf Hunderte GPUs verteilt und am Ende zusammengeführt wird. Theoretisch wissen wir, wie man einen EVM-Verifizierer baut, der eine Berechnung in O(log(N)) Zeit beweist: Eine GPU erledigt jeden Schritt, dann gibt es einen „Aggregationsbaum“:
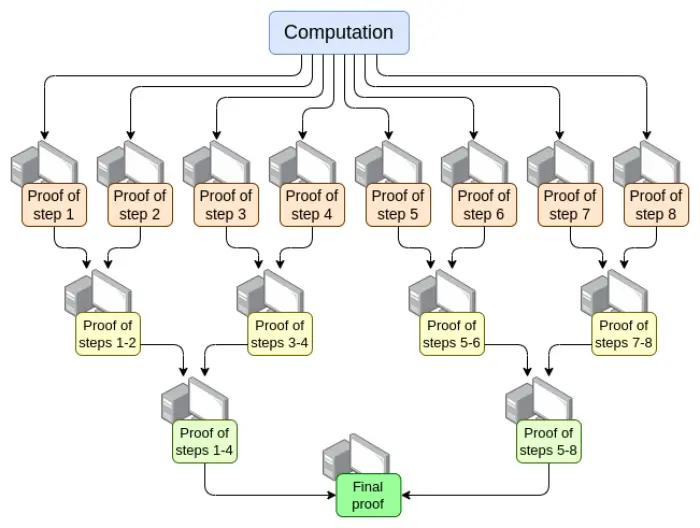
Die Umsetzung ist herausfordernd. Selbst im schlimmsten Fall, wenn eine sehr große Transaktion den gesamten Block ausfüllt, kann die Berechnung nicht nach Transaktionen, sondern nur nach Opcodes (EVM oder RISC-V) aufgeteilt werden. Die Konsistenz des „Speichers“ der VM zwischen den verschiedenen Beweisteilen sicherzustellen, ist eine Schlüsselherausforderung. Wenn wir jedoch solche rekursiven Beweise erreichen, ist das Latenzproblem der Beweiser zumindest gelöst.
- Optimierung des Beweissystems – Neue Beweissysteme wie Orion, Binius, GRK und andere werden die Verifizierungszeit für allgemeine Berechnungen wahrscheinlich erneut drastisch verkürzen.
- Weitere Änderungen der EVM-Gas-Kosten – Viele Dinge in der EVM können optimiert werden, um sie für Beweiser günstiger zu machen, insbesondere im schlimmsten Fall. Wenn ein Angreifer einen Block bauen kann, der den Beweiser zehn Minuten blockiert, reicht es nicht, einen normalen Ethereum-Block in 4 Sekunden zu beweisen. Die nötigen EVM-Änderungen lassen sich grob in folgende Kategorien einteilen:
- Änderungen der Gas-Kosten – Wenn eine Operation lange zum Beweisen braucht, sollte sie auch dann hohe Gas-Kosten haben, wenn sie rechnerisch relativ schnell ist. EIP-7667 ist ein Vorschlag, der die Gas-Kosten für (traditionelle) Hashfunktionen stark erhöht, da deren Opcodes und Precompiles relativ günstig sind. Um das auszugleichen, können wir die Gas-Kosten für EVM-Opcodes mit niedrigen Beweiskosten senken, sodass der durchschnittliche Durchsatz gleich bleibt.
- Ersetzung von Datenstrukturen – Neben dem Austausch des Statusbaums durch eine STARK-freundlichere Methode müssen auch Transaktionslisten, Receipt Trees und andere teure Strukturen ersetzt werden. Etan Kisslings EIP zur Umstellung von Transaktions- und Receipt-Strukturen auf SSZ ist ein Schritt in diese Richtung.
Darüber hinaus helfen die in der vorherigen Sektion erwähnten Tools (Multi-Dimensional Gas und verzögerter Status-Root) auch hier. Im Unterschied zur zustandslosen Verifizierung gilt aber: Mit diesen Tools haben wir genug Technik für das, was wir aktuell brauchen, aber für vollständige ZK-EVM-Verifizierung ist noch mehr Arbeit nötig – nur eben weniger als bisher.
Ein nicht erwähnter Punkt ist die Beweiser-Hardware: Schnellere Beweiserzeugung mit GPU, FPGA und ASIC. Fabric Cryptography, Cysic und Accseal sind drei Unternehmen, die hier Fortschritte machen. Das ist für L2 sehr wertvoll, aber für L1 wahrscheinlich kein entscheidender Faktor, da L1 hochgradig dezentral bleiben soll, was bedeutet, dass die Beweiserzeugung im Rahmen normaler Ethereum-Nutzer bleiben muss und nicht durch einzelne Firmenhardware limitiert werden darf. L2 kann hier aggressivere Kompromisse eingehen.
In diesen Bereichen gibt es noch mehr zu tun:
- Parallelisierung von Beweisen erfordert, dass verschiedene Teile des Beweissystems „gemeinsamen Speicher“ (wie Lookup-Tabellen) nutzen können. Die Technik ist bekannt, muss aber implementiert werden.
- Wir brauchen mehr Analyse, um das ideale Set an Gas-Kosten-Änderungen zu finden, das die Worst-Case-Verifizierungszeit minimiert.
- Wir müssen mehr Arbeit in die Beweissysteme stecken
Mögliche Trade-offs:
- Sicherheit vs. Beweiserzeit: Aggressivere Hashfunktionen, komplexere Beweissysteme oder aggressivere Sicherheitsannahmen oder andere Designs können die Beweiserzeit verkürzen.
- Dezentralisierung vs. Beweiserzeit: Die Community muss sich auf die „Spezifikation“ der angestrebten Beweiser-Hardware einigen. Sind große Entitäten als Beweiser akzeptabel? Wollen wir, dass High-End-Consumer-Laptops einen Ethereum-Block in 4 Sekunden beweisen können? Oder etwas dazwischen?
- Grad der Rückwärtskompatibilitätsbrüche: Andere Defizite können durch aggressivere Gas-Kosten-Änderungen ausgeglichen werden, aber das könnte die Kosten für bestimmte Anwendungen unverhältnismäßig erhöhen und Entwickler zwingen, Code neu zu schreiben und neu zu deployen, um wirtschaftlich zu bleiben. Auch diese beiden Tools haben ihre eigene Komplexität und Nachteile.
Wie interagiert das mit anderen Teilen der Roadmap?
Die Kerntechnologien, die für L1-EVM-Gültigkeitsbeweise benötigt werden, überschneiden sich weitgehend mit zwei anderen Bereichen:
- L2-Gültigkeitsbeweise („ZK rollup“)
- Zustandslose „STARK Binär-Hash-Beweis“-Methoden
Mit erfolgreichen Gültigkeitsbeweisen auf L1 wird Single-Staking einfach: Selbst die schwächsten Computer (einschließlich Handys oder Smartwatches) können staken. Das erhöht den Wert, andere Single-Staking-Beschränkungen (wie das 32ETH-Minimum) zu lösen.
Außerdem kann ein EVM-Gültigkeitsbeweis auf L1 das Gas-Limit von L1 erheblich erhöhen.
Gültigkeitsbeweise für den Konsens
Welches Problem wollen wir lösen?
Wenn wir einen Ethereum-Block vollständig mit SNARK verifizieren wollen, ist die EVM-Ausführung nicht der einzige Teil, den wir beweisen müssen. Wir müssen auch den Konsens beweisen, also den Teil des Systems, der Einzahlungen, Auszahlungen, Signaturen, Validator-Bilanz-Updates und andere Elemente des Ethereum Proof of Stake behandelt.
Der Konsens ist viel einfacher als die EVM, aber die Herausforderung ist, dass wir keine L2-EVM-Convolution haben, also muss die meiste Arbeit ohnehin erledigt werden. Jede Implementierung eines Beweises für den Ethereum-Konsens muss daher „von Grund auf“ erfolgen, auch wenn das Beweissystem selbst auf gemeinsamer Arbeit aufbauen kann.
Was ist das und wie funktioniert es?
Die Beacon Chain ist wie die EVM als Statusübergangsfunktion definiert. Die Statusübergangsfunktion besteht hauptsächlich aus drei Teilen:
- ECADD (zur Verifizierung von BLS-Signaturen)
- Pairing (zur Verifizierung von BLS-Signaturen)
- SHA256-Hash (zum Lesen und Aktualisieren des Status)
In jedem Block müssen wir für jeden Validator 1-16 BLS12-381 ECADD beweisen (möglicherweise mehr als einen, da Signaturen in mehreren Sets enthalten sein können). Das kann durch Subset-Precomputation-Techniken kompensiert werden, sodass wir sagen können, dass pro Validator nur ein BLS12-381 ECADD bewiesen werden muss. Derzeit gibt es pro Slot 30000 Validator-Signaturen. In Zukunft, mit Single-Slot-Finality, könnte das in beide Richtungen variieren: Bei der „Brute-Force“-Variante könnten es bis zu 1 Million Validatoren pro Slot werden. Mit Orbit SSF bleibt die Zahl bei 32768 oder sinkt auf 8192.
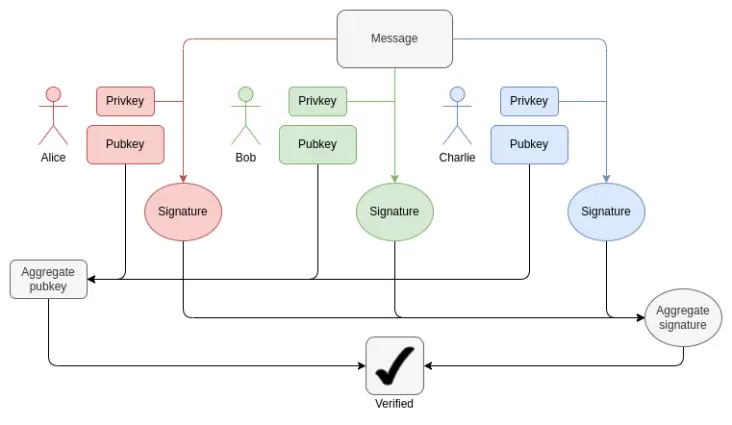
Wie BLS-Aggregation funktioniert: Die Verifizierung der Gesamtsignatur benötigt pro Teilnehmer nur ein ECADD, nicht ein ECMUL. Aber 30000 ECADD sind immer noch eine große Beweismenge.
Was Pairings betrifft, so gibt es derzeit maximal 128 Beweise pro Slot, also 128 Pairings. Durch ElP-7549 und weitere Änderungen kann das auf 16 pro Slot reduziert werden. Pairings sind selten, aber extrem teuer: Jeder Pairing-Lauf (oder -Beweis) dauert Tausende Male länger als ein ECADD.
Eine der Haupt-Herausforderungen beim Beweis von BLS12-381-Operationen ist, dass es keine Kurve mit Ordnungszahl gleich der Feldgröße von BLS12-381 gibt, was jedem Beweissystem erheblichen Overhead beschert. Andererseits ist der für Ethereum vorgeschlagene Verkle-Baum auf der Bandersnatch-Kurve aufgebaut, sodass BLS12-381 selbst die native Kurve für SNARK-Systeme zur Verkle-Branch-Verifizierung ist. Eine einfache Implementierung kann 100 G1-Additionen pro Sekunde beweisen; um die Beweisgeschwindigkeit ausreichend zu erhöhen, sind fast sicher clevere Techniken wie GKR nötig.
Für SHA256-Hashes ist der schlimmste Fall derzeit der Epoch-Transition-Block, bei dem der gesamte Validator-Short-Balance-Tree und viele Validator-Bilanzen aktualisiert werden. Jeder Validator-Short-Balance-Tree ist nur ein Byte, also werden 1 MB Daten neu gehasht. Das entspricht 32768 SHA256-Aufrufen. Wenn für tausend Validatoren der Saldo einen Schwellenwert über- oder unterschreitet, müssen die Validator-Records aktualisiert werden, was etwa zehntausend Hashes bedeutet. Das Shuffling benötigt pro Validator 90 Bits (also 11 MB Daten), kann aber zu jedem Zeitpunkt innerhalb einer Epoche berechnet werden. Bei Single-Slot-Finality können diese Zahlen je nach Situation steigen oder sinken. Shuffling wird überflüssig, obwohl Orbit es teilweise wieder einführen könnte.
Eine weitere Herausforderung ist, dass für die Verifizierung eines Blocks der gesamte Validator-Status einschließlich der Public Keys erneut geladen werden muss. Bei 1 Million Validatoren sind allein die Public Keys 48 Millionen Bytes plus Merkle-Branches. Das bedeutet, dass pro Epoche Millionen von Hashes benötigt werden. Wenn wir die Gültigkeit von PoS beweisen müssen, ist eine realistische Methode eine Form von inkrementell verifizierbarer Berechnung: Im Beweissystem wird eine separate, für effiziente Nachschlagevorgänge und Updates optimierte Datenstruktur gespeichert und deren Updates bewiesen.
Zusammengefasst gibt es viele Herausforderungen. Um sie effizient zu bewältigen, ist wahrscheinlich eine tiefgreifende Neugestaltung der Beacon Chain nötig, die möglicherweise mit dem Übergang zu Single-Slot-Finality einhergeht. Merkmale einer solchen Neugestaltung könnten sein:
- Änderung der Hashfunktion: Heute wird der „volle“ SHA256-Hash verwendet, sodass wegen Padding jeder Aufruf zwei Kompressionsfunktionsaufrufe benötigt. Mit der SHA256-Kompressionsfunktion gäbe es mindestens den doppelten Gewinn. Mit Poseidon könnten wir einen 100-fachen Gewinn erzielen, was alle Probleme (zumindest bei Hashes) löst: Bei 1,7 Millionen Hashes pro Sekunde (54MB) könnten selbst 1 Million Validator-Records in wenigen Sekunden in den Beweis geladen werden.
- Bei Orbit: Direktes Speichern der geshuffelten Validator-Records: Werden z.B. 8192 oder 32768 Validatoren für einen Slot als Komitee ausgewählt, werden sie direkt nebeneinander im Status gespeichert, sodass mit minimalem Hashing alle Public Keys in den Beweis geladen werden können. Auch alle Bilanzupdates werden so effizient.
- Signaturaggregation: Jede leistungsfähige Signaturaggregation beinhaltet eine Form von rekursivem Beweis, wobei verschiedene Nodes im Netzwerk Zwischenbeweise für Signatur-Subsets liefern. So wird die Beweisarbeit auf viele Nodes verteilt und die Arbeit des „Endbeweisers“ stark reduziert.
- Andere Signaturschemata: Für Lamport+Merkle-Signaturen braucht man 256+32 Hashes zur Signaturverifizierung; multipliziert mit 32768 Signierern ergibt das 9437184 Hashes. Mit optimierten Signaturschemata kann das durch einen kleinen konstanten Faktor weiter verbessert werden. Mit Poseidon wäre das in einem Slot beweisbar. In der Praxis ist eine rekursive Aggregation schneller.
Bezug zu bestehender Forschung?
- Succinct Ethereum consensus proofs (nur für Sync Committee)
- Succinct Helios in SP1
- Succinct BLS12-381 Precompile
- Halo2-basierte BLS-Aggregat-Signaturverifizierung
Was bleibt zu tun, welche Trade-offs gibt es?
Tatsächlich benötigen wir Jahre, um einen Gültigkeitsbeweis für den Ethereum-Konsens zu erhalten. Das entspricht ungefähr der Zeit, die wir für die Einführung von Single-Slot-Finality, Orbit, Änderungen an Signaturschemata und die nötige Sicherheitsanalyse brauchen, um genügend Vertrauen in „aggressive“ Hashfunktionen wie Poseidon zu haben. Daher ist es am klügsten, diese anderen Probleme zu lösen und dabei die STARK-Freundlichkeit zu berücksichtigen.
Die Hauptabwägung wird wahrscheinlich in der Reihenfolge der Maßnahmen liegen: zwischen einem schrittweisen Ansatz zur Reform der Ethereum-Konsensschicht und einem radikaleren „alles auf einmal“-Ansatz. Für die EVM ist ein schrittweiser Ansatz sinnvoll, da er die Rückwärtskompatibilität am wenigsten beeinträchtigt. Für die Konsensschicht ist die Rückwirkung geringer, und eine umfassendere Neugestaltung der Beacon Chain, um sie optimal für SNARKs zu machen, ist vorteilhaft.
Wie interagiert das mit anderen Teilen der Roadmap?
Bei einer langfristigen Neugestaltung von Ethereum PoS muss STARK-Freundlichkeit oberste Priorität haben, insbesondere bei Single-Slot-Finality, Orbit, Änderungen an Signaturschemata und Signaturaggregation.
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
4E: Das abnehmende illiquide Bitcoin-Angebot könnte eine Preisrallye unterdrücken
Eine tiefgehende Analyse von Talus: Wie digitale Arbeitskräfte unsere Arbeitsweise verändern
Untersuchung, wie Talus durch eine auf Blockchain basierende KI-Agenten-Vertrauensinfrastruktur ein autonomes digitales Wirtschaftssystem aufbaut.
